pega-interview-questions
Pega is a low-code platform that lets companies unify their processes and customer journeys from beginning to end. In the application market, low code is a relatively new word. It usually refers to an application that allows you to develop code using a simple interface rather than having to write it yourself. These applications help you write code by writing it for you. Rather than learning a programming language, you simply learn how to use the software, and it takes care of the rest. Drag and drop graphic interfaces make it easy to learn how to utilize the software. Although you must learn how to use the application, being an expert in Pega is significantly easier than becoming an expert in .NET or Java.
Pega eliminates one of the most significant roadblocks to modern business: the proliferation of applications and systems. The Pega Platform allows enterprises to have a single view of a customer, a case, and a workflow, as well as all the accompanying data and intelligence, by establishing a customizable platform that sits above your other systems. Its platform allows for the creation of completely customizable user interfaces. Its browser-based applications make it convenient because no software installation is required. It allows for the learning of past behaviour through adaptive analytics.
Pega Interview Questions for Freshers
1. What do you mean by workspace or studio in the context of Pega? What are the different types of workspaces offered by Pega?
A workspace is a place where you can use specialized tools and functionalities. You may let team members focus on tasks that fit with their expertise by using different workspaces to create and administer your application.
Pega Platform offers four studios, or role-based authoring workspaces and they are as follows:
- App Studio
- Dev Studio
- Prediction Studio
- Admin Studio

Each studio speeds up application development and increases productivity by giving users role-based capabilities.
Using role-based workspaces in the Pega Platform can help you increase productivity. Users may see what they require when they require it. Front-end developers, for example, can work in one workspace to create interface channels, while system administrators can switch between workspaces to configure additional features and monitor run-time outcomes.
Multiple workspaces are available to users. The system opens the default workspace when users log in. Users have access to various workstations and can switch between studios.
2. Explain about classes in Pega. What are the different types of classes available in Pega?
The Pega Platform allows users to reuse rules across case types and applications. Developers frequently reuse rules in their systems, ranging from single data pieces to complete processes. Reusing rules increases the quality of an application while also cutting down on development time. Pega Platform divides rules into classes based on their re-usability inside an application. Each cluster is referred to as a class. Each application is made up of three different class kinds.
- Work Class: Processes, data items, and user interfaces are all part of the Work class, which provides the rules that govern how to process a case or cases.
- Integration Class: The Integration class holds the rules that specify how the application interacts with other services, such as the integration resources that connect it to a customer database or a third-party web server.
- Data Class: The rules that specify the data objects used in the application, such as a customer data type or order items data type, are stored in the Data class.
When we add a rule in App Studio, it automatically selects the proper class. We can concentrate on what we want the rule to accomplish rather than how to develop it. We can write the rule in Dev Studio if you need control over the class. Switching to Dev Studio is a good idea if we want to write a rule that we can reuse in another app.
3. What do you mean by a work object in the context of Pega? How do you create a work object in Pega?
A work object is the most basic unit of task completion in an application, as well as the most basic collection of data on which a flow runs. Work objects are generated, updated, and eventually closed when an application is used (resolved). A unique ID (property pyID), an urgency value, and a status are all assigned to each work object (property pyStatusWork). A work object is also known as a work item in some companies.
Work objects under specific application settings may have a traditional name from the pre-automation era. Work objects in a help desk or service desk system, for example, are frequently referred to as trouble tickets.
We can create a work object in Pega in the following steps :
- Create a button that looks like a section or a header.
- Click the action tab after expanding the cell property within the button.
- Add an action set to the button.
- The button should have a focus class and a flow name.
- With “Param.prevRecordkey,” we can get the current work object ID.
- Open the case with "Obj-Open-By-Handle."
- Copy the data from pagers with Page-Copy.
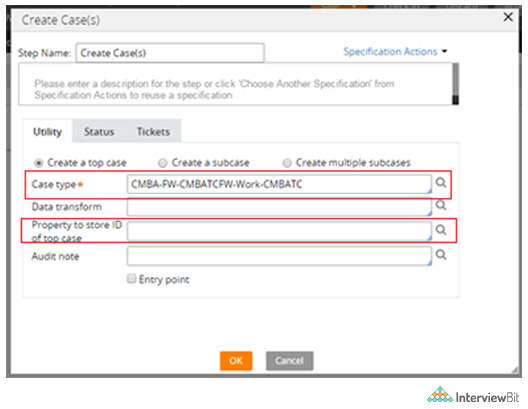
Also, a work object can be created from an activity. To create a workpage for the case type we desire, we use the activity "createWorkPage." The data transform that will be used to initialise properties might be specified. If it's a stand-alone work object, use "addWork," and if it's a covered work object, use "addCoveredWork."

4. What do you understand about DCO in Pega? What are the benefits of DCO in the context of Pega?
DCO stands for Direct Capture of Objectives. It is the process of acquiring, organising, and storing data by using Pega's integrated solution, the Pega Platform. Processes and tools for gathering and organising application artefacts are included in DCO. More crucially, IT, business, and testing teams, as well as other resources, employ this enabling technology. It saves time, effort, and money while also improving the quality of projects and people's lives.

DCO is not a methodology or a step in the methodology development process. It's not just one tool. Instead, the goals and benefits are to centralise the data so that it may be used continually across departments at the right time and at the right level. DCO eliminates communication obstacles by providing a centralised repository for linked application artefacts (objectives, requirements, specifications, and implementation rules). All resources have real-time as-built documentation and a single view of the application.
The following tools are used by DCO to automate the work:
- Case Lifecycle Manager
- New Application Wizard
- Application profiler
- Document generation
- Effort Estimation
- Specification documents
Following are the benefits of DCO in Pega:
- DCO enables collaborative teams to model situations that must be addressed by the application's end users. The modelling and simulation tools allow users to take a critical interim step after documenting the application but before incurring the cost of development to see if the software is meeting our objectives. When we can think through and work out solutions as part of the software development life cycle, we are less likely to be blindsided in production.
- Organizations can use DCO to improve their efforts and use iterative processes. Issues and risks are not allowed to be discovered and mitigated at the conclusion of a project; they are detected and mitigated in real-time. The software development process is more visible, and it allows teams to learn and improve on a constant basis. DCO technologies and best practices give organisations several ways to deliver go-live, increasing their return on investment and allowing them to reliably accomplish their objectives.
5. What do you know about SLA in the context of Pega? What is its importance?
SLA is an acronym for Service Level Agreement. It is one of the most useful features of the Pega CRM platform. As part of the case management process, Service Level Agreements allow us to set targets and timelines. The major goal of SLA is to assist the task force in completing all tasks on time. Pega Rules Process Commander will keep track of each SLA rule's performance of a specific event action that was configured for that rule. By increasing the urgency number, also adjusts the urgency associated with that assignment. This may draw attention to the item on the employee's to-do list because it necessitates attention. So we can sort the work-list based on the task's urgency.

A Service Level Agreement (SLA) establishes time intervals as a goal and time frame for standardizing how you solve work in your application. It establishes a time limit for completing the work. Pega establishes an SLA when we set a goal and a deadline. Service levels can be set for processes, steps, stages, and entire classes.
There are four levels in SLA. They are as follows:
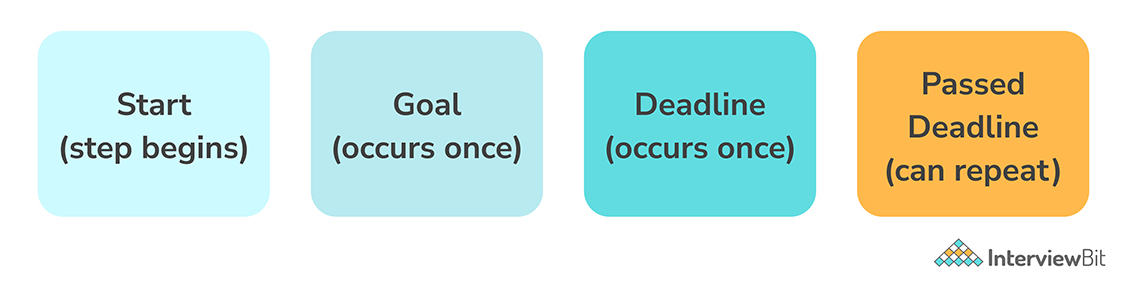
- Start: This is the point at which the service level timer starts ticking. It all starts at the zeroth hour.
- Goal: Its purpose is to specify how long the assignments should take. This step is counted from the start of the assignment or case.
- Deadline: The term "deadline" refers to the amount of time a case or process can take before it is considered late. It is calculated from the start of the assignment or case.
- Passed Deadline: When the assignment or case has passed the deadline, the term "passed deadline" is used to indicate when further action should be taken. It calculates the amount of time that has elapsed since an assignment's deadline.
Following are the benefits of SLA :
- SLA ensures that your service provider and you are on the same page as far as standards and services are concerned. Setting explicit and measurable rules is vital since it reduces the possibility of client dissatisfaction and provides remedies if the commitments are not met.
- SLAs mention recourse to be taken in case of service commitments failure. If your service provider fails to meet their duties, it will have serious ramifications for your company's reputation. As a result, if performance standards are not reached, we must incorporate repercussions in the SLA.
- Your clients will have peace of mind with SLA. They have a contract that they may refer to in order to hold their service provider accountable and to specify the type of service they anticipate. They can lessen some of the consequences if the agreed-upon conditions are not reached by receiving financial compensation from their supplier.
6. What are the different types of SLA? Explain them.
Following are the different types of SLA:
Assignment SLA: Assignment SLA is an SLA that refers to an assignment. This SLA begins with the creation of the assignment and ends with the completion of the assignment. The assignment urgency is set in the attribute pxUrgencyAssignSLA on the newly Assigned Page.
Case Level SLA: When an SLA is referred to at the case level, it is referred to as a Case level SLA. This SLA is relevant throughout the lifecycle of a case. It begins when a case is opened and concludes when the case is closed. The standard property pySLAName is used to identify this SLA under the workpage. It's set in pyWorkPage's pxUrgencyWorkSLA parameter. The pxUrgencyWorkSLA property under pyWorkPage controls the urgency of case-level SLAs.
Stage Level SLA: When an SLA is referred to at the stage level, it is referred to as Stage level SLA. It begins when a case enters a stage and ends when it exits the stage. The pxUrgencyWorkStageSLA property under pyWorkPage controls the urgency at the Stage level.
Step level/Flow level SLA: An SLA is considered a Step level or Flow level SLA when it is referred to as a step or flow level. A step-level SLA begins when a process or step is initiated and ends when it is completed. When a flow is begun, a flow level SLA is started, and when a flow is stopped, it is stopped. If a step SLA is present, it takes precedence over a flow SLA. Step SLA can be referenced in every step under the stage in the case type rule. The process tab of the flow rule refers to a flow SLA. The pxUrgencyWorkStepSLA property under pyWorkpage controls the flow or step level urgency.
7. Describe the different types of layout available in Pega.
Following are the different types of layout available in Pega:
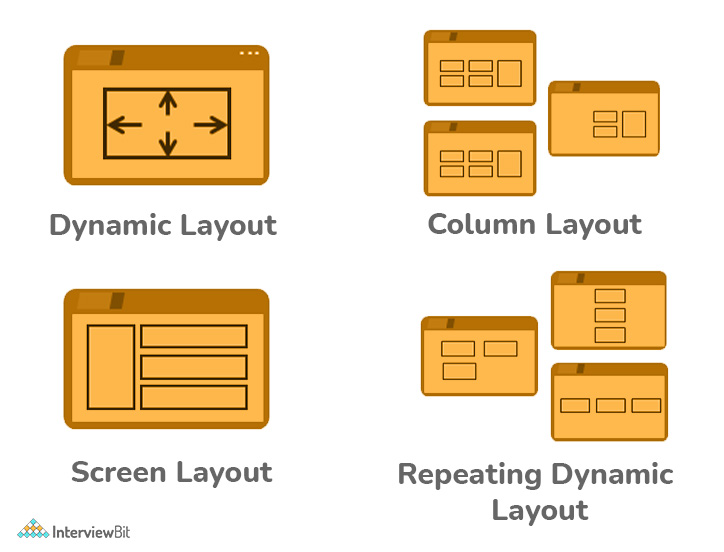
- Screen Layout: Screen layouts are only used within a harness and are typically used to establish portals for an application.
- Dynamic Layout: A dynamic layout is a DIV-based layout that allows content to be displayed in a variety of ways.
- Column Layout: A Columns layout allows you to show major content, like a work item, alongside supporting stuff, like an attachment.
- Grid Layout: Table layouts make it easier for users to obtain and compare data. Tables can be used as a flexible base for users to process vast volumes of data in your apps. Tables in price comparison software, for example, can assist customers in quickly identifying the best deal.
- Tree Grid Layout: The properties in pages in an embedded Page List property can be viewed, navigated, and accessed using a tree layout. To identify entries of current interest, the user can swiftly extend and collapse branches of the tree.
In sections, dynamic layouts and column layouts are employed. In a dynamic or column layout, you can add content to a section, such as properties, controls, and other sections. The format of the skin determines the positioning, alignment, width, and arrangement of components in a layout.
8. How would you create a dynamic layout in Pega?
Following steps must be followed to create a dynamic layout in Pega :
- Look for and open a Section form that already exists.
- Expand the Structural list on the Design tab, then drag the Dynamic layout onto the work area.
- Click the View properties icon in the Dynamic layout header.
- Set the layout format in the Properties window in either of the following ways:
- Choose one of the predefined formats.
- Select Other and then specify the custom layout format in the adjacent field to use a skin-defined custom layout format.
- Select when you want the Dynamic layout to appear in the Visibility field in either of the following ways:
- Choose one of the pre-defined options.
- Select Condition (expression) and then the Open condition builder icon to construct your own condition.
- Submit the form.
9. Explain Page-Validate and Property-Validate methods in the context of Pega. How are they different from one another?
- Page-Validate: This method is used to check all of the properties on a page. If a page has embedded pages, this method validates all of the attributes in a recursive manner. This method is time-consuming and uses a lot of system resources. Use the Obj-Validate method with the Rule-Obj-Validate rule to validate specified properties.
- Property-Validate: This method is used to set limits on the value of a property. To implement constraints, use the Edit validate rule in conjunction with the Property-Validate method. The Property-Validate method can be used to validate multiple properties.
10. Explain about Access Groups and Access Roles. Differentiate between them.
Access Group :
Access Group is used to restrict access to our application’s functionality. To accomplish varying levels of access control, we can create multiple access groups for the same application.
An access group decides on the following:
- After logging in, users can access the portals.
- The roles, or privileges, that users have access to.
- Advanced parameters are applied to new rules, such as the default rule-set name and version.
The Operator ID of a user is used to associate an access group with that user. When a user logs in with more than one access group established, the application associated with the principal access group is used. Privilege inheritance can also be used by security managers to make the process of allowing the user access to a feature protected by privilege easier. The Data-Admin-Operator-AccessGroup class defines access groups.
Access Roles :
Through the Access of Role to Object and Access Deny rule types, access roles determine the classes that a user can see, alter, and delete.
To grant permissions (capabilities) to users, use an access role name. In requestor type and access group instances, access roles can be mentioned. For a range of users, the Pega Platform includes built-in access roles ( names that begin with PegaRULES: ):
- Guests
- Administrators
- Developers
- Authenticated work users
The Rule-Access-Role-Name rule type defines access roles.
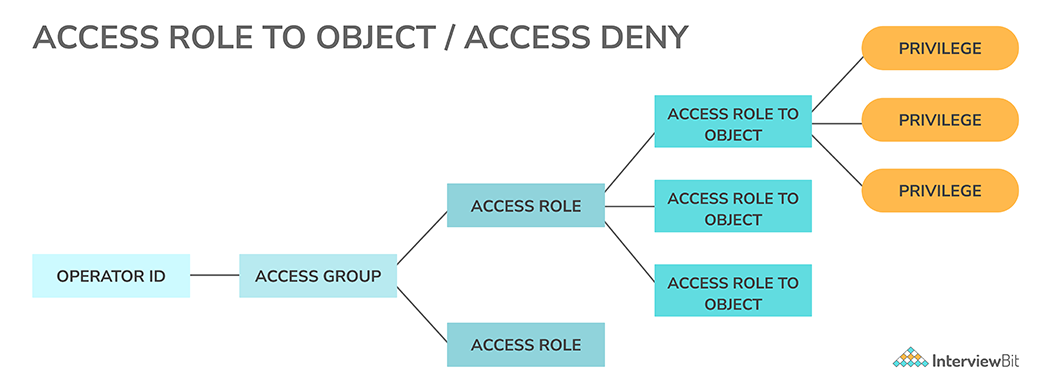
Difference :
- Authorizations are granted according to a user's access group rather than their role. The degree of authorization for the access group is determined by the most permissive role in the access group.
- A list of Data-Admin-Operator-AccessGroup instances is displayed on the Access Groups tab. The table shows the system's access groups and the number of operators assigned to each group whereas for the present application, the Access Roles tab displays a list of Rule-Access-Role-Name rules. You can examine, add, and remove roles from this tab.
11. Explain Requestor Type in Pega. What are the different types of Requestor types in Pega?
A Data-Admin-Requestor instance defines a requestor type. The BROWSER requestor type, for example, indicates characteristics of interactive user connections, such as guest connections, utilizing Internet Explorer or another web browser. Agents employ the BATCH requestor type for background processing.
Pega Platform comes with four requestor types for the system name we specify during installation, as well as a reserved requestor type prpc.BROWSER for exceptional cases. Typically, we only require the four requestor types that contain your system name. If we want to modify the system name after installation, we go to Designer Studio => System => Settings => System Name to get to a landing page tab where we can do so. When we change a system's name, new requestor instances are created that correspond to the previous name's instances. If the prior system name did not include all requestor types for some reason, the missing requestors are also produced when the system is renamed.
Following are the different requestor types in Pega:

- Application:This is used by listeners and external client systems to access the Pega Platform, such as through a service request (other than JSR-168 requests using Rule-Service-Portlet rules). Requestor IDs that begin with the letter A are used in requestor sessions that use this requestor type instance.
- Batch: This is used by listeners, services, agents, and daemons all executing background processing. The requestor ID for requestor sessions using this instance begins with the letter B. All BATCH requestors have access to the PRPC:Agents access group when it is first implemented. If you make a change to Data-Admin-Requestor.BATCH so that it no longer has access to the PRPC:Agents access group and subsequently upgrades the Pega Platform, the system may fail to start.
- Browser: This is used for accessing the Pega Platform portal via a web browser via HTTP or HTTPS, or from a browser displaying a Pega composite application. The requestor ID for requestor sessions utilising this instance begins with the letter H. All BROWSER requestors have access to the PRPC:Unauthenticated access group when it is first implemented.
- Portal: This is used in conjunction with Service Portlet rules, for HTTP access as a portlet. The requestor ID for requestor sessions utilising this instance begins with the letter P.
12. Explain Flow Action in the context of Pega. What are the different types of Flow Actions available?
A flow action is a decision that users can make as an interim or final disposition for an assignment they're working on. The Rule-Obj-FlowAction rule type is used to define each flow action.

There are two sorts of flow actions:
- Connector Flow Actions: On a Visio presentation, connector flow actions appear as lines in the Diagram tab of a flow rule. A line emerges from an assignment shape and terminates at the flow's next shape. Users select a connector flow action during runtime, complete the assignment, and move the work item along the connection to the next form.
- Local Flow Actions: When a local flow action is selected at runtime, the assignment remains open and on the worklist of the current user. The Assignment Properties panel records local flow actions that aren't displayed on the flow diagram.
Take, for example, an application that facilitates employee recruitment operations. When completing an assignment that requires the employee to evaluate the quality of a candidate (based on a résumé and application form), the employee enters his judgments and reasoning in the application and then selects one of three flow actions: Advance, Reject, or MoreInfo. These flow actions may employ distinct user form displays, such as in the action section of a perform harness or in a modal dialogue, and may require different input fields.
13. Explain PRPC in the context of Pega. What are the benefits of PRPC?
PRPC stands for Pega Rules Process Commander. Pegasystems is built on the PRPC foundation. It is totally model-driven, allowing the creation of dependable and efficient applications without the use of any code, including SQL, Java, CSS, or HTML. PRPC is a software platform that enables companies to combine all of their diverse, complex business procedures and methods into a single platform. It allows you to combine multi-stream processing into a single system by automating, documenting, and simplifying business processes.

Pega PRPC is made up of two unique entities.
- Process Commander: Sets of pre-configured rules that serve as a foundation for customization and development.
- Pega Rules: A Java-based Object-Oriented Rules Engine powers PEGA Rules.
PRPC attempts to achieve the following business benefits :
- Businesses can use the PRPC platform to combine all of their independent, separate, and multiple business procedures and rules into a single platform.
- It enables corporate processes to be automated, documented, and streamlined.
- Multi-stream methods can be combined into a single system.
- Data can be transferred between frameworks and processed, segregated, and decoded.
- The purpose of PEGA PRPC is to cut down on the costs of any adjustments.
14. Explain activities in the context of Pega. What are the best practices while using activities?
Activities in Pega Platform automate processing. Activities are scripted in Dev Studio and consist of a series of stages that must be completed in the order specified. When more appropriate rule types are unavailable, usually due to more sophisticated computations or procedures, or when a rule requires an activity to run, activity rules automate the system. Declare On change, for example, necessitates the usage of an activity to start a process or pause work when the value of a particular property changes. Control returns to the rule that called the action after the activity is completed.
For example, an insurance firm is obligated to upload insurance claims to the Registry of Motor Vehicles. To minimize the impact on users, automated uploads take place during off-peak hours. An activity can be configured in Pega Platform to allow the system to automate claim uploads without the need for user participation.
Following are some of the best practices that one should keep in mind while using activities in Pega :
- Keep activities to a minimum. Limit your actions to no more than 25 steps, and make sure that each one is focused on achieving a single goal.
- Use alternate rule types whenever possible, such as a data transform to set a property value.
- Hand-coded Java should be kept to a minimum. When standard or custom rule types, library functions, or activity methods are available, skip the Java stages in activities.
15. Explain the decision table and decision tree in the context of Pega. What are the differences between them?
Decision Table:

In case of a decision table, the values in a column in a decision table evaluate against the same property/operator pair, such as Gender =. When developers need to analyse several different combinations of the same set of properties or conditions in order to produce a single value or property, they can use a decision table. For example, a corporation determines bonus eligibility based on the number of years spent at the company and ratings on five employee assessment measures.
Decision Tree:
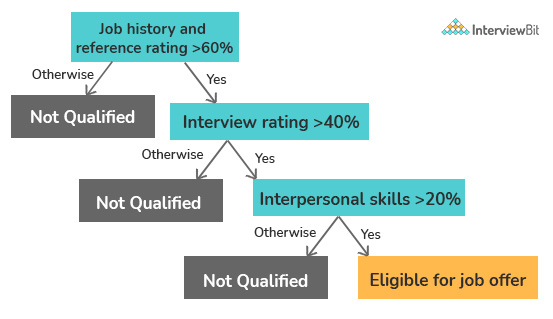
In a decision tree, each branch compares the property/operator pair to a single value in order to take an action, such as returning a value or evaluating a nested condition. When evaluating requirements on multiple attributes that are reliant on other conditions, developers might employ a decision tree. In a decision tree, each branch is assessed, and any branches that evaluate to true perform the action that follows, such as continuing the evaluation to the nested condition. A language learning software, for example, is doing significant A/B testing, with some users receiving hearts and others receiving stars for their efforts. Hearts and stars have their own properties with their own worth. Based on the number of hearts or stars linked with the account, a decision tree examines the various prizes that users are qualified for.
When a comparison evaluates to true, both decision tables and decision trees analyze characteristics or conditions to deliver outcomes. Decision trees evaluate against distinct characteristics or conditions than decision tables, which evaluate against the same set of qualities or conditions.
A business stakeholder or low-code developer can easily configure and change dependent conditions that evaluate against distinct characteristics due to the decision tree's line-by-line layout. When a decision table is used in a circumstance where several criteria evaluate against the same property, the decision table will include empty boxes where a value is not required for the conclusion. A business stakeholder or low-code developer can easily configure and change a decision that evaluates against many of the same properties due to the decision table's table structure.
16. Explain Rule Resolution in the context of Pega. What are its benefits?
The search technique used by the system to discover the best or most appropriate rule instance to apply in a given is known as rule resolution.
Except for a few rule types — classes that inherit from the Rule- class — rule resolution applies to all rule types. Instances of classes derived from the Work-, Data-, or any other base class are not affected by rule resolution.
Despite the fact that the rule resolution process is fast and invisible, it is critical to comprehend how it works. Make key component value selections based on how you want rules to be found via rule resolution when you construct applications. The rule resolution process can be speed up by using an in-memory rule cache. If the system discovers an instance (or instances) of the rule in question in the cache, it accepts the candidate rules from the cache and bypasses many steps in the resolution process.
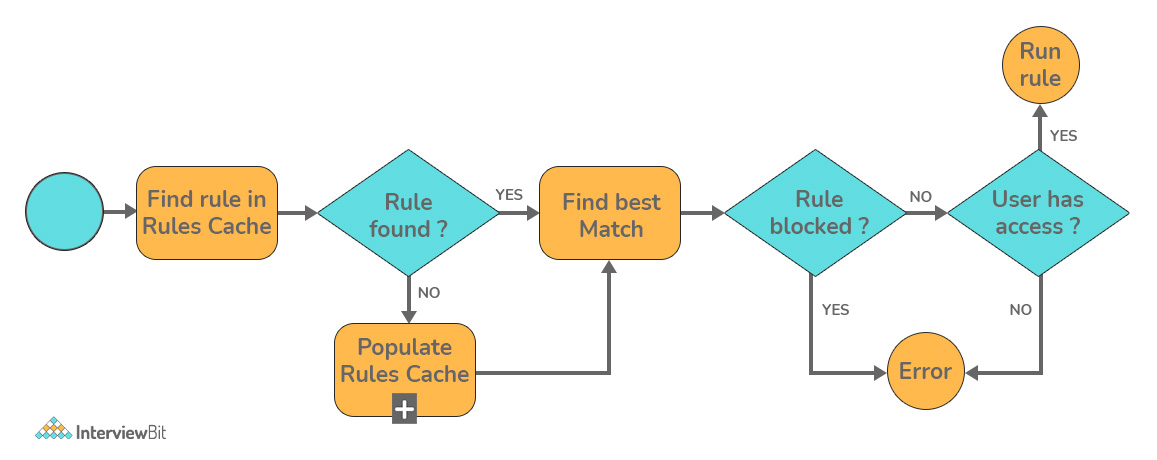
The following are some of the advantages of rule resolution:
- Across apps and organizations, rules can be shared. Object-oriented software development has many advantages, including sharing and reuse.
- More explicit rules stated at a lower level can override rules defined at a higher level. While this reduces the value of sharing, it gives much-needed flexibility while highlighting exceptions.
- Even inside a single rule-set, rules might have many versions, and security rules limit which users view and execute which versions. This makes application development, testing, and patching easier.
- With little conflicts and interference, a single Pega Platform system can host many apps, multiple organizations, and multiple versions of a single application.
- Applications can be built independently of one another, but they can all be based on the same set of rules that are locked (and hence will not change).
17. Explain declarative rule in the context of Pega.
A declarative rule is an instance of a subclass of the Rule-Declare-class.
In a Declare Expression, Constraints, Declare On Change, or Declare Trigger rule, we can specify needed relationships among attributes. When the value of a property is involved in any of these declarative rules, the system checks an internal dependency network for other values that are affected and does other processing based on the network's configuration. This is referred to as Forward chaining.
Most declarative rules are reevaluated after the following types of events:
- When users upload an input form, it is evaluated at the end of the input processing.
- During the execution of an activity, assessment takes place at each step, after the method has completed but before the evaluation of a transition in that phase.
- As control passes from one job (one shape on the Visio flow diagram) to the next during flow execution.
- When the work item progresses from one form to another and within connectors at the end of a flow transition (if a relevant property is set).
- When the value of any of the attributes involved in the rule changes, index rules are activated.
- When an object is saved to the database, trigger rules are activated.
Decision tree rules, decision table rules, and case match rules do not employ forward chaining and are only assessed when explicitly requested.
18. What do you mean by an agent in the context of Pega? Explain.
An agent is a server's internal background process that performs actions on a regular basis. Agents deliver email notifications about assignments and outgoing messages, generate updated indexes for the full-text search feature, synchronize caches among nodes in a multiple node system, and other system duties. Agents are self-contained and asynchronous: the activities they invoke operate on their own timetables, and a second activity execution can begin before the first one has finished.
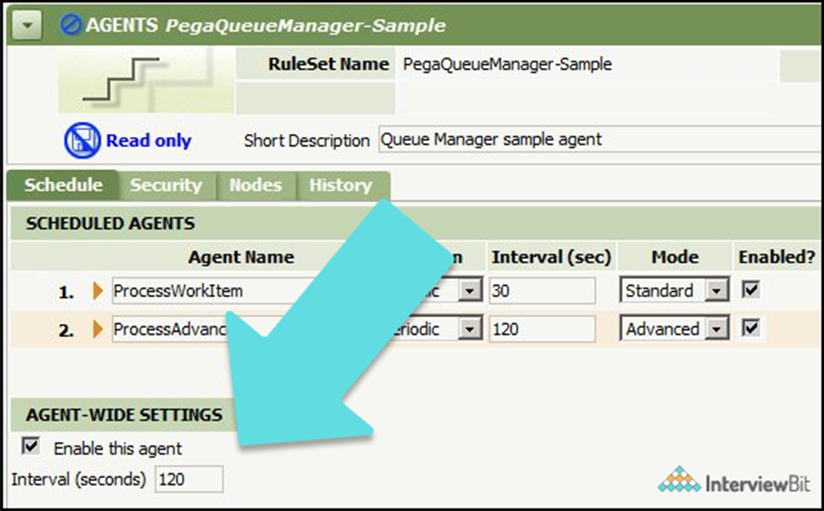
Agents are defined by their own set of rules (Rule-Agent-Queue rule type). Agent Queue data instances are used to enable and schedule agents (Data-Agent-Queue class). If potential deadlock and other locking issues are appropriately managed by the activities in a multi node cluster, an agent can execute on numerous nodes, even each node, to achieve high throughput.
19. Explain data pages in the context of Pega.
A data page in a Pega Platform application retrieves data from a specified data source and caches it in memory. The integration to the data source is managed by a data page, which separates business activities from any integration details. This separation enables app developers to use supplied data in their apps without having to know the data source or connection specifics. Unlike most Pega Platform pages, applications seek to populate the contents of a data page only when the page is requested, rather than through an explicit action. Data pages are classified as declarative rules since their content is available on demand. To distinguish a data page from other pages in memory, Pega Platform automatically adds the characters D_ to the name.
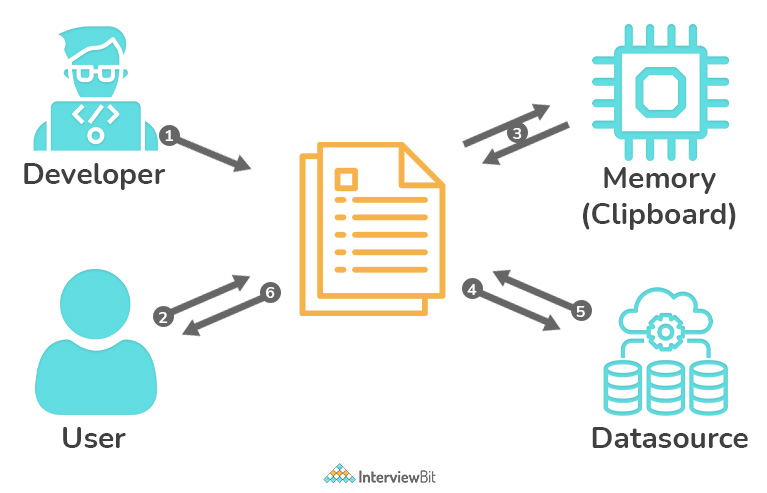
A developer must give four crucial pieces of information when creating a data page. They are as follows :
- Structure of the page
- Object Type of the page’s content
- Edit Mode supported
- Scope of the data page
Pega Interview Questions for Experienced
20. Explain Case Management in the context of Pega. What are its benefits?



Comments
Post a Comment